Our tech-saturated world can’t exist without data. All of that data not only needs various places to go—which our global telecommunications infrastructure and the ever-expanding Internet of things represents—but must also have a safe haven. This is where the best data storage solutions come in.
Your organization has unique data storage needs that no one-size-fits-all approach can precisely meet. We understand that at Connection. And in the interest of helping you find the best data storage tools and practices, and assisting you in gaining a greater understanding of data on a macro and micro level, we’ve compiled this Data Storage Buying Guide.
Your organization has unique data storage needs that no one-size-fits-all approach can precisely meet. We understand that at Connection. And in the interest of helping you find the best data storage tools and practices, and assisting you in gaining a greater understanding of data on a macro and micro level, we’ve compiled this Data Storage Buying Guide.
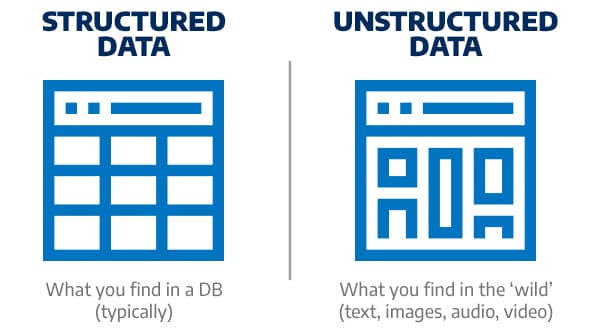
Structured vs. Unstructured Data: Overview and Essential Considerations
While the full spectrum of the data universe involves dozens of classifications, understanding the difference between structured and unstructured data is key.Structured
Any data that is based upon and adheres to a predefined model—within a table with set values like a Microsoft Excel spreadsheet, for example—is considered structured. These models—including common frameworks, such as ERP and CRM tools—are usually referred to as relational databases.Unstructured
The structured data model, however, leaves out a fair portion of the data you can find within servers, drives, computers, smartphones, and other devices. Unstructured data is comprised of everything from audio and video files to images and documents, including RTF, Docx, etc. The files themselves have structure, but they’re not quantified or organized the way that pieces of structured data are. Basically, unstructured data constitutes anything outside of the clearly defined data-model structures, including metadata, which is technically unstructured but, by virtue of being “data about data,” can be used for rudimentary organization and classification.From a data storage perspective, the main difference between structured and unstructured data is the sheer volume of unstructured data makes it easier to eventually run out of space. Unstructured data’s primary characteristic—the lack of a relational model through which it can be more easily categorized—also complicates things somewhat.
However, the options available to your organization for storing both unstructured and structured data have never been more diverse. There are many choices, and we can help you make the right data storage decisions for your organization.







Nothing Stacks Up to EPYC™
Stay confident with AMD modern security features that help keep data safe
Most Popular Storage



Important Data Storage Considerations

Capacity
How much can it fit? That’s the question that data capacity measurements answer about all of your organization’s data. You start with bytes, and exponentially increase to kilobytes, megabytes, gigabytes, terabytes, exabytes, zettabytes, and yottabytes.When dealing with data storage for organizations, you’ll most often be talking about terabytes, but it’s not entirely outside the realm of possibility that you may need to start reckoning with petabytes.
It’s generally a sound decision to purchase data storage solutions with a capacity to meet your organization’s immediate needs, but always keeping an eye on the future. You don’t want to get caught purchasing storage for your startup operations without considering potential growth in the coming years. Pursuing scalability should always be a major priority in your quest for the optimal storage solution—with the ability to scale up or scale out as the needs of your organization demand.
Classification
Data classification is the process by which you group data into relevant categories, in the interest of boosting its value at the point of application and/or protecting it from unauthorized access. Various tags and labels are involved to ensure all data sets can be readily identified.There are three primary methods of data classification:
- Content-based: Entails inspecting and interpreting files to track down sensitive information, and determining the level of accessibility (i.e., public or restricted)
- Context-based: Data is sorted based on factors, including who is using it, where it is going, and what applications are associated with it
- User classification: Various tags are added regarding the data’s sensitivity, usage, etc.
Growth Rates
There’s nothing like looking at the macro nature of data to put your organization’s needs into perspective.IDC estimated in 2018 that all of the data in the world amounted to 33 zettabytes and projected that by 2025, we would reach 175ZB—a 61% growth rate. The U.S.’s own data growth is expected to slow somewhat, but is more the exception than the rule.
When considering your own organization’s data storage needs, it is important to project the rate at which your data will grow, as well as how your business will grow. For example, will you be expanding slowly, but steadily or taking on new customers in large swaths? You need to factor in all relevant key performance indicators to make these calculations: everything from revenue figures and overall budget to staffing, research, and development.
Data Speed and Its Importance
Data speed might lead you to think of how fast a YouTube video loads on your smartphone. But on an enterprise level, while the megabits or gigabits per second of your Internet connection is certainly important (1-10Gb/s and 10-40Gb/s are common transfer rates over copper and optical fiber, respectively), you’ll need to consider the measure of cycles more than anything else, when considering storage needs.The processors in quality enterprise-grade servers are capable of reaching RAM cycles of at least 2GHz. Depending on the specifics of your organization and the types of data you typically handle, you might want to go higher—opting for something like 3.4 or 3.7GHz. This is not a hard-and-fast rule, however. An organization that deals with a large amount of data, but doesn’t often access it, would be better served by a lower-GHz server, from a cost-efficiency perspective.
Faster and Smaller Storage
Just about everything in tech is moving in the direction of faster and smaller—why should data storage be any different?There are more than a few servers out there that run at high-processor clock speeds, like 3.5GHz, while also being on the smaller side (i.e., between 10 and 25 pounds). But it may not always be possible for you to find the exact combination of ideal size and fast-paced cycling when you’re on the lookout for servers and other forms of physical data storage. Take your budget, organizational needs, the types of data you handle, and even your office space into account during your search. After all, those drives will have to go somewhere, and relying solely on cloud storage is most likely not a feasible solution.
Access
All the data in the world isn’t worth much, if the people who need it can’t access it when necessary. Your organization’s data storage solution must properly accommodate all access needs, from anywhere. The number of users accessing it must also be a critical concern, especially on a larger enterprise scale. In such settings, hundreds of individual users may be poring over many data sets at the same time, looking for the assurance that your IT infrastructure can support them without incident. Last but not least, latency and bandwidth factor greatly into data access. If your organization’s broadband will not allow for efficient data transfers on a consistent basis, or if your data storage equipment won’t support high bandwidth and facilitate low latency―leading to bottlenecking―you’ll find yourself in trouble.Security
As discussed earlier, the privacy level of various data sets is one of the primary methods by which it can be classified, making security a major factor in data storage. For any storage solution, be it on premises, in the cloud, or a combination of the two―it makes sense to be compatible with the stipulations laid out in ISO/IEC 27040 and guided by a combination of physical controls, including keycard-only access, biometric data locks, temperature controls, smoke detectors, CCTV camera monitoring, dedicated security personnel, and technical security measures. Technical security measure refers to appropriate levels of encryption, for starters, as well as anti-malware features, robust firewalling, traffic profiling and more.On a practical, day-to-day level, keeping firm control over credentials is extremely important to security, so all of your storage hardware and software should allow for the creation of tiered access—meaning each user only has the bare-minimum access needed for essential job duties and no more.
Useful though ISO 27040 can be, its security protocols may come secondary to organizations that have government- or industry-mandated compliance requirements. These range from PCI for anyone handling customers’ credit or debit card information to the strict protections of personal medical data that HIPAA requires. Failing to observe those rules, or other security compliance frameworks with tight restrictions, can quickly lead to hefty fines and other penalties. In the long run, the optimal data storage solution should be capable of meeting whichever standards your organization is obligated to follow, as well as ISO 27040 that covers a great deal of what’s included in more specific requirements.
Resiliency
The first part of data resiliency—the physical aspect—is arguably discussed far less often than backup and recovery, but it’s a mistake to deny its importance. After all, if your data storage hardware can’t withstand the actual physical damage of electrical surges and other similar incidents, it won’t matter how well the other aspects of your data and business continuity plan are set up. Strong shock absorption is essential for every physical component of your overall data storage solution.Resiliency also encompasses things that are more abstract than the physical endurance of a drive or a bank of servers. Specifically, it includes the long-term advance planning that plots out how your organization will respond in the event of various worst-case scenarios—everything from equipment failures to power outages in the local grid and even natural disasters or other forces majeure. Redundancy, meanwhile, represents the key way in which these data strategies are underwritten, namely, through chains of supplementary storage components and systems, including power backups, that take over the moment the initial system shuts down unexpectedly. Server clustering and snapshots—virtual freeze-frames of specific moments in time within a server array—add more muscle to the backup strategy, as do Redundant Arrays of Inexpensive Disks (RAIDs).
Data Systems
We previously cited structured and unstructured data as the two primary categories into which all data falls; but there are a considerable number of subcategories too.
Major types of structured data, and systems that facilitate their transmission and storage, include:
Major types of structured data, and systems that facilitate their transmission and storage, include:
- Block: Data stored in identically sized portions within a file system. The sizes of blocks vary widely, but are often tiny like 4KB.
- Applications: Specific data within a relational database application, such as a customer relationship management platform.
- ERP: Enterprise resource planning software is one of modern businesses’ most commonly used tools, due to its integrated, real-time oversight of essential process data organized via common relational models.
- DB: A typical structured, relational database.
- FC: Fibre channel systems help transmit structured data between data centers at high speeds (up to 128Gbps).
- iSCSI: A data transport protocol that helps link separate data storage facilities, usually via block-level access managed over standard TCP/IP networks.
- FCoE: Data center bridging (DCB) networks require Fibre Channel over Ethernet (FCoE) support to transport fibre channel data successfully and efficiently.
- SAN: Storage Area Networks reorganize data from multiple sources connected to a common user network in various repositories. They are often used in data centers that store information belonging to the largest enterprises.
- Backup data: Copied from a primary source and stored apart from it, backup data is used to restore operations in the event of that original source’s failure. Data from a full backup is a 100% identical copy. Incremental backups, meanwhile, copy only data that has changed since the last backup operation, while differential backups represent the aggregated data from multiple incremental backups.
- Files: Individual pieces of data.
- Shares: Various methods by which data is made available to those outside the database itself. Public URLs (and the data comprising them) are a common choice.
- NFS: Data shared via a distributed file system protocol from a network to an individual device, usually (but not always) within the context of Unix and Linux operating systems.
- CIFS: This represents the data shared via the Common Internet File System—Microsoft’s Server Message Block protocol, used by legacy devices running on Windows. (If you have some of this data bouncing around your system, it’s old.)
- SMB: Unlike the defunct CIFS, SMB is very much still in play. This distributed file system was last updated in 2016 for Windows 10 and Windows Server 2016.
Types of Data Storage
The Basic Binary: Internal vs. External
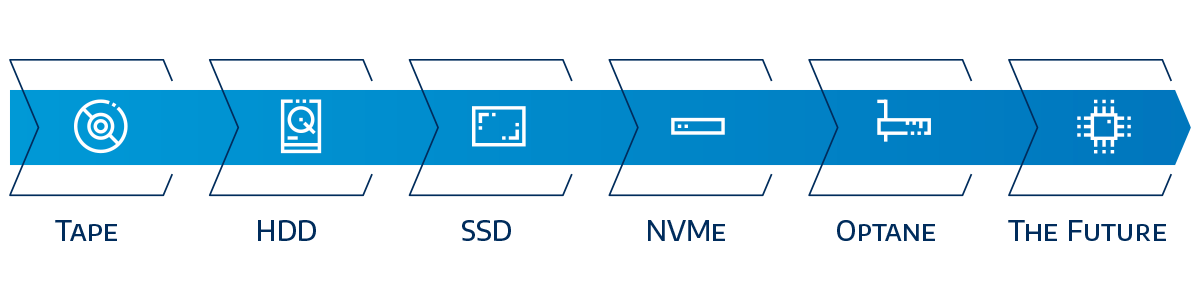
Is it inside a device or can it be held as a physical object? That’s the main difference between internal and external storage. Both are essential in various circumstances, though some individual types have narrower uses than others.Hard Disk Drives and Solid State Drives
Until recently, the vast majority of computers ran on fast-spinning internal hard drives. HDDs can also be external devices that connect and disconnect from various computers as needed.SSDs, which use flash storage instead of a spinning disk, are faster and much smaller than their counterparts, use less power than external HDDs, and also operate more efficiently, and often noiselessly. On the other hand, they’re more expensive. For data storage on a user-by-user basis, you’ll have to choose carefully. Using each for different applications—SSDs when portability and speed are of the essence and HDDs to maximize storage—is ultimately your best bet.
Direct-attached vs. Network-attached Storage
Companies at the smaller end of the SMB spectrum undoubtedly need some data storage, but not a lot. A direct-attached storage system, which can be as simple as an external hard drive or two, may be all they need.But realistically, most businesses aren’t that small, falling somewhere more in the middle or SME territory. They will be best served by a network-attached data storage system, consisting typically of several drives attached to a hardware controller and united by a core RAID network. This layout offers enough processing and storage power for the majority of SMEs, and can easily be scaled up by adding drives to the RAID set.
Disk and Tape Backups
When things go awry and you have to rely on your backup tools to ensure business continuity after a disaster, you’ll either be backing up onto disks, tapes, or both. Some people are particularly fond of one or the other. Disk partisans cite the ability for easy deduplication and faster recovery, while those who prefer tape love it for its low cost, ruggedization (allowing for safe physical transport), extremely high storage capacity (a single modern LTO tape can hold 30TB), and long life span due to its stateless nature. As with most things, the best answer may be a mixture of both―tape for data you need to store the longest and disks to back up data that you’ll access at the beginning of your recovery.SAN Storage
Scale up far beyond what DAS can offer and you arrive at SAN systems. These transfer data at the block level between servers and storage devices, and keep it securely within that framework. SANs are appropriate for any organization that must handle information on a massive scale.Converged and Hyper-converged Data Systems
Both converged infrastructure and hyper-converged infrastructure data systems serve the same purpose. They unite networking, computing, storage, virtualization, networking, and management tools all under one roof, simplifying data storage infrastructure in slightly different ways. CI’s functions are more contingent on its hardware and a direct connection to the physical server, while HCI is largely software-based and virtualized.Network Attached Storage Buying Guide
Explore our definitive network attached storage (NAS) buying guide, offering insights into essential features, storage capacities, top brands, and key considerations to help you choose the right NAS solution for efficient data management and storage.
Data Storage Business Problems and Use Cases

Ultimately, what your organization specifically needs from a data storage solution is going to dictate which solution you go with and the tools you use. The following represent a few use cases and the storage approach best suited for each one.
For unstructured data, a small business could begin with something as simple as direct-attached storage with an external hard drive or two. Midsize companies would be better equipped with network-attached storage, which involves a division of data storage and support labor between an easily scalable, network-united collection of drives. Larger enterprises, however, may want to seriously consider highly scalable NAS or even object-based storage platforms.
Accelerating Your Applications
When your company’s mission-critical applications aren’t performing as fast, or as well in general, as they need to, everyone loses. If this is your most pressing need, a hyperconverged infrastructure solution may be your best bet. HCI comprises a unique combination of powerful servers and software to manage storage, compute, and network virtualization, and boost app performance.Creating More Space for Files
If you need more space, you can theoretically choose most any data storage option that provides more capacity than what you currently have, but it’s unfortunately not that simple. You will need to choose a data storage solution, based on the capacity and data needs of your specific organization.For unstructured data, a small business could begin with something as simple as direct-attached storage with an external hard drive or two. Midsize companies would be better equipped with network-attached storage, which involves a division of data storage and support labor between an easily scalable, network-united collection of drives. Larger enterprises, however, may want to seriously consider highly scalable NAS or even object-based storage platforms.
With regard to structured data, there are entry-level SAN arrays on the market that can provide small and medium-sized businesses with reliable and resilient data services. Higher-end workloads that require extremely low latency and the ability to scale on demand may drive an organization to look into more robust SAN offerings, or potentially examine virtualized SAN/Software Defined Storage.
The public cloud―Amazon Web Services, Microsoft Azure, Google AppEngine, among others―is usually the most inexpensive choice, while still offering solid resiliency and scalability. Private cloud is more appropriate for companies with stricter security or regulatory compliance requirements, while also offering users more flexibility and control overall.
Hybrid cloud combines elements of both, and we believe is the best cloud storage choice now and for the future. We’re more than ready to help you find the perfect combination of public and private cloud for your organization.
Looking at the Cloud
Even though it’s no longer new, cloud storage’s possibilities are still exciting. And we get it―many businesses don’t have the physical space required to store all data on-premises. But you must be careful which cloud option you choose between public, private, and hybrid. And remember that hardware counts here too; it’s just that you’re relying on someone else’s server hardware, far away.The public cloud―Amazon Web Services, Microsoft Azure, Google AppEngine, among others―is usually the most inexpensive choice, while still offering solid resiliency and scalability. Private cloud is more appropriate for companies with stricter security or regulatory compliance requirements, while also offering users more flexibility and control overall.
Hybrid cloud combines elements of both, and we believe is the best cloud storage choice now and for the future. We’re more than ready to help you find the perfect combination of public and private cloud for your organization.
Data Storage FAQs
Some questions about storage come up more often than others, so we wanted to provide substantive answers to a few of them:
There’s certainly a lot to consider and, ultimately, choose from. But making the right choice can be much simpler than you think. The key? Giving careful consideration to the type of data that’s being written to the device. Connection’s data specialists can help you find the right single type, or the ideal mix, of storage media to keep your data accessible, resilient, and secure.
That’s okay. We work with customers who take data security just as seriously as you do―from financial and healthcare institutions to numerous federal government agencies, including the Department of Defense. We can be as hands-on or hands-off as you need us to be. More often than not, we can give you the guidance you need to run diagnostic tools yourself, and then you can share the relevant information with us in keeping with your individual compliance structure. The bottom line is this: No matter what your essential security protocols entail, we can partner with you to safely assess your environment, so that any future purchases of data storage products and services are made with as much relevant insight as possible.
They’re similar, but not the same. Snapshots are kind of like a backspace button―one that will let you revert to a previous point in time. They’re quick to perform and take up very little space. Because of this, snapshots can be taken frequently and provide a readily accessible undo function for rapid remediation. But a snapshot alone cannot serve this purpose because it is ultimately reliant upon the actual data within the array. A snapshot is not a physical copy of that data, but only references a moment in time for that storage device.
Backups, on the other hand, are full copies of all data within a given drive or array, typically stored on a secondary device. If the primary array goes down, the isolated backup data can be used to recover the environment. Because they are true physical copies, if one were to backup 10TB every day, they would consume 70TB of capacity each week. Backups can also be very time- and resource-consuming. There are certain technologies available, like deduplication and compression, that can minimize the impact on resources that backups entail. Although, it’s still more common for organizations to run backups much less frequently than they do snapshots. The important thing is to balance the two in a way that minimizes risk and data loss exposure, while making the most effective possible use of the resources and budget available.
Backups, on the other hand, are full copies of all data within a given drive or array, typically stored on a secondary device. If the primary array goes down, the isolated backup data can be used to recover the environment. Because they are true physical copies, if one were to backup 10TB every day, they would consume 70TB of capacity each week. Backups can also be very time- and resource-consuming. There are certain technologies available, like deduplication and compression, that can minimize the impact on resources that backups entail. Although, it’s still more common for organizations to run backups much less frequently than they do snapshots. The important thing is to balance the two in a way that minimizes risk and data loss exposure, while making the most effective possible use of the resources and budget available.
No. In fact, quite the opposite. Tape is still a proven and cost-effective way to archive valuable information, in keeping with your organization’s long-term data retention policy. While the cost of cloud and disk-based storage has come down in terms of cost per TB, there’s still nothing out there quite as cost-effective as tape media. Moreover, tape is transportable in a way that its counterparts aren’t. In other words, the data being protected can easily be shipped off-site and stored at another location, providing true isolation in the event of a localized disaster. While it’s not always the perfect solution for everyone, tape archiving is certainly still a viable component to business continuity and disaster recovery strategies, and should be taken into serious consideration as you try to work out the ideal storage system for your organization.
Common Data Storage Buying Pitfalls
No purchase process is ever perfect. Companies make mistakes all the time when shopping for equipment and services, and data storage is no exception. These are some of the most common problems and errors that may arise and you should try to avoid at all costs:
One Box to Rule Them All
Sometimes purchasing and implementing a multi-protocol array that can support all of your various data types can be a huge boost to operational efficiency. But if you end up writing cold and rarely used data onto expensive hot storage media, it’ll cost you in the long run!The Perils of Getting Set in Your Ways
Tried-and-true solutions should always be given consideration. They’ve earned that reputation for a reason, after all. If we didn’t believe it, we wouldn’t have cited the benefits of tape storage earlier in this guide. But it’s also important to explore the bleeding edge. New technologies are developed and rapidly adopted by end users for a reason, so don’t be afraid to think outside the box.Some Now, More Later. Then Even More, Even Later.
You can’t buy storage without considering how quickly your data sets are growing and, for many customers, budget doesn’t always afford the opportunity to buy now for future requirements. Whether you choose scaling up or scaling out, it’ll be best to establish a long-term plan in advance. Otherwise, you might risk patchworking silos of storage as needs pop up over time.“We Think We Need…”
Let the Connection data solutions team run an assessment! There are some things that you just don’t have to guess about, and the current health and performance of your data center infrastructure is one of them. Any successful refresh project should include a formal deep-dive into the data behind the data. That way, our proposed solutions can be most effectively optimized for your unique workloads once they are implemented.Data Storage Glossary of Terms

Key terms used in this buying guide, and worth knowing as you look for the perfect data storage solution, are listed below:
- BCDR (Business Continuity and Disaster Recovery): The formal planning and processes used by organizations to determine how data is backed up outside of its primary storage media in the event of equipment failures, power outages, and other worst-case scenarios.
- Block Storage: Structured data, stored in identically sized portions within a file system.
- CIFS (Common Internet File System): A now-outdated distributed file system for Windows machines.
- Cloud Storage: Using the public, private, or hybrid cloud as a primary repository for data, typically in conjunction with various physical storage methods.
- CRM (Customer Relationship Management): A platform using structured databases to manage a business’s dealings with separate clients, frequently employed by sales agents, as well as project and account managers.
- DAS (Direct Attached Storage): Storage systems directly attached to or within the host computer like an external hard drive, for example.
- Data Backup: Tools and raw data used to restore operations in the event of an original data source’s failure. Data backup can be full, incremental, or differential.
- Data Compression: Reducing the space required to store unique data without actually altering the data itself.
- Data Deduplication: Removing duplicate data from your storage system to free up space.
- Data Recovery: Using backups and related methods to ensure that data lost in any catastrophic incident isn’t lost forever.
- Data Replication: Storing data in multiple nodes to distribute access more readily and provide redundancy.
- Database: A system for the storage and classification of structured data, as found in CRM or ERP platforms, among many others.
- Effective Capacity: The data storage capacity of a solution adjusted for compression, deduplication, and other techniques to create extra space.
- ERP (Enterprise Resource Planning): One of modern businesses’ most commonly used tools, due to its integrated, real-time oversight of essential process data organized via common relational models.
- FCoE (Fibre Channel Over Ethernet): A support method for the successful and efficient transport of fibre channel data, via a frame in an Ethernet network.
- Fibre Channel: A system for transmitting structured data among servers, data centers, and other physical storage at high speeds (up to 128Gbps).
- File Share: Distributing files between different users, storage media, or networks.
- File Storage: All methods by which data is retained.
- Hard Disk Drive (Spinning): The backbone of any computer or laptop’s data storage, in its internal form. As external devices, HDDs can be switched back and forth between different devices.
- HCI (Hyper Converged Infrastructure): A software-based approach to data storage architecture that combines storage, networking, and compute functionality. Similar to converged infrastructure, but not dependent on hardware like converged infrastructure.
- High Availability Failover: Multiple host devices working together to benefit various data backup functions.
- Hybrid Storage Array: A storage system that combines hard drives and solid state drives for cost-efficient high performance.
- IOPS (Input/Output Per-Second): Measurement of maximum reads and writes to non-contiguous locations. Used, somewhat controversially, as a metric for assessing HDD and SDD performance.
- iSCSI (Internet Small Computer Systems Interface): A system by which data that helps link separate data storage facilities is shared, usually via block-level access managed over standard TCP/IP networks.
- LTO (Linear Tape-Open): One of the newest magnetic backup formats (debuting in 2017), capable of storing up to 30TB on a single tape.
- NAS (Network Attached Storage): Multiple drives connected to a single network and working together with one another.
- NFS (Network File System): A distributed file system protocol for sharing data between a network and an individual device, usually (but not always) within the context of Unix and Linux operating systems.
- Object Storage: A method of data storage that organizes using objects as opposed to files or blocks.
- RAID (Redundant Array of Independent Disks): A group of several different hard drives that unite to serve the function of one larger, less efficient drive.
- RAIN (Reliable Array of Independent Nodes): Same principle as RAID, but with nodes instead of disk drives.
- Read and Write Cache: Storage component containing records of both reads and writes (as opposed to one or the other).
- SAN (Storage Area Network): These individualized networks are used to aggregate data from multiple sources connected to a common user network in a single repository.
- SAS (Serial Attached SCSI): Used for data transfers between different hard drives or tape drives.
- SATA (Serial ATA): For connecting and transferring data from hard drives to computer systems. Ideal for RAID setups.
- Scale-Out Architecture: Using this approach, you add more nodes to your data storage infrastructure to handle increased demands.
- Scale-Up Architecture: The opposite of scaling out, scaling up involves adding more storage space to a single existing node for the same purpose.
- SCM (Supply Chain Management): A structured database used to trace the life cycle of a product from design to final sale.
- SMB (Server Message Block): A distributed file system used on Windows-based devices, succeeding the now-defunct CIFS.
- Snapshot: A tool used in data recovery that represents a record of the data in a particular storage device at a specific time.
- Software Defined Storage: Storage operations overseen and controlled entirely by software.
- Solid State Drive: An external hard drive reliant on flash storage instead of a spinning disk. Faster, smaller, and quieter than an HDD; also considerably more expensive.
- Storage Latency: The time between an application’s initiation of a storage operation and notification of the operation’s completion.
- Structured Data: Any data that is based upon and adheres to a predefined model, usually stored within a relational database.
- Tape Storage: Using magnetic tape to store digital data, usually as a backup medium in the event of issues affecting servers, drives, or the cloud.
- Thin Provisioning: A practice that allocates storage across multiple applications to eliminate wasted space.
- Unstructured Data: All data that does not conform to any predefined model of a database (e.g., most audio, video, and image files, among many others).
- VSA (Virtual Storage Appliance): A controller used with a virtual machine to maximize a machine’s storage space.
- VTL (Virtual Tape Library): A system of multiple hard drives that backs up tape data by mimicking the operations of a physical tape library.
13